最近我看到了一个有趣的视频【鸟叫声的三维体现】 ,通过某种算法将鸟叫声绘制在了三维坐标中。这让我产生了强烈的好奇心:这样的可视化有什么意义?它能用来做什么?
初探声音的”三维世界”
声音本质上是一种振动,传统上我们使用波形图或频谱图来表示它。
想象你要记录一个连续变化的波浪。如果你只用文字描述这个波浪,可能会很困难。但如果你沿着波浪每隔一段固定距离就测量一次高度,然后把所有这些高度值连起来,就能近似地还原出波浪的形状。
数字照片是空间的高维结构:每个像素有RGB三个值,所有像素组成的矩阵就是照片的高维表示。相邻像素间的空间关系构成了图像内容。
数字音频是时间的高维结构:每个采样点单个像素,看似只是振幅数字。但连续采样点间的时间关系(波形变化)构成了声音的“图像”。就像像素组合成边缘、纹理,采样点组合成音调、音色等听觉特征。
然而波形图或频谱图,并不能反应人的音色,语言的句式结构等复杂信息。但将声音映射到三维空间,让我们能够从全新的角度观察声音的特征和结构。
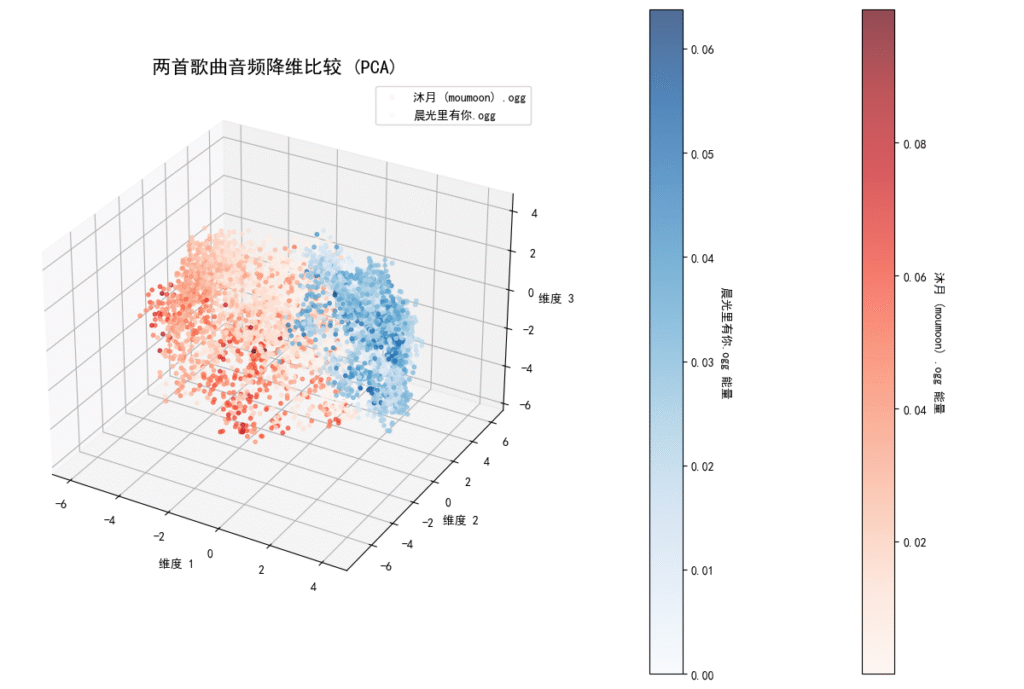
我首先尝试使用主成分分析(PCA)技术,将两首不同风格歌曲的音频数据进行降维处理。每段音频都被分割成许多小片段,每个片段有60多个特征维度,我使用PCA将这些高维数据压缩到我们能够直观理解的三维空间。
简单解释一下PCA:想象你有一堆在多个维度上分布的数据点,我们没办法视觉观察高纬结构的特征。所以PCA的目标就算找到一个最佳的观察角度,让你能在三维空间中看到这些高纬数据点之间最明显的差异。
分析结果很有趣:
- 两首歌的中心点明显分离,距离达到4.3个单位
- 它们的分布范围也不同,表明音频特征有显著差异
- 在三维空间中,两首歌的音频片段确实分布在不同的区域
=== 统计分析结果 ===
歌曲1中心点: [-2.09450279 -0.37006448 -0.31934641]
歌曲2中心点: [2.09450279 0.37006448 0.31934641]
两首歌中心点距离: 4.3016
歌曲1分布范围(标准差): [1.91407585 2.50499429 1.57101622]
歌曲2分布范围(标准差): [0.96306112 1.66113684 1.84670616]
两首歌音频特征相似度: 差异较大
从音乐到人声:声纹识别的可能性
这个发现让我产生猜想:既然不同歌曲在声音空间中位置不同,那么不同人的说话声音是否也会有独特的”空间签名”?代表着人的口音,嗓音粗细等信息。这可能是声纹识别的一种新思路。
验证思路就算对比人声在空间中的分布,看看会不会不同?
于是我邀请了一位朋友(男性,带有闽南语口音)与我(男性,普通话略好一丢丢,QaQ)一起朗读同一段文字,使用相同的录音设备。结果印证了猜想。
PCA结果:
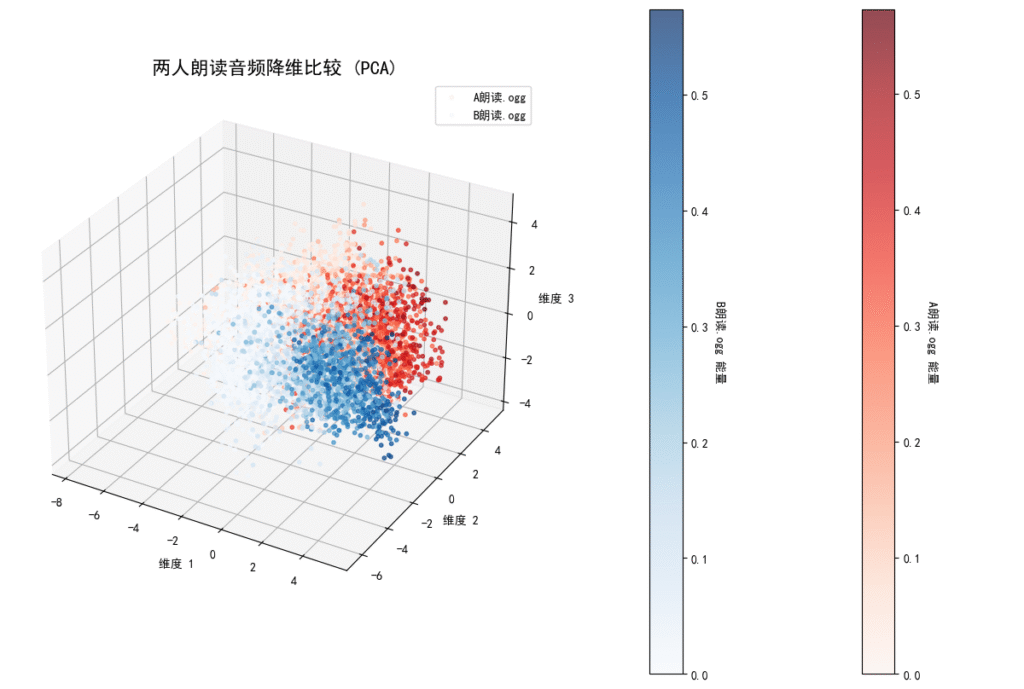
人声朗读对比
PCA
=== 统计分析结果 ===
A中心点: [0.23291338 1.0100605 0.32674812]
B中心点: [-0.23291338 -1.0100605 -0.32674812]
两人声朗读中心点距离: 2.1737
A分布范围(标准差): [2.19198087 1.53562504 1.61154289]
B分布范围(标准差): [2.5012327 1.57993654 1.35136674]
两人声朗读特征相似度: 差异较大
诶确实,可以发现。两个人的声音在这个二维空间中被分开了。而且从PCA的结果可以看出高能量的采样点都集中于维度1的正方向上,且二人采样点分离较开,产生假设一:高能量声音更能区分每个人的说话特征。
PCA分析结果:
- 两个人的声音中心点距离为2.17个单位
- 分布范围相似但位置明显分离
- 高能量的声音片段(音量较大的部分)更集中在特定方向
TSNE结果:
简单解释t-SNE:与PCA不同,t-SNE更注重保留数据点之间的局部关系,特别擅长展现数据中的聚类结构。
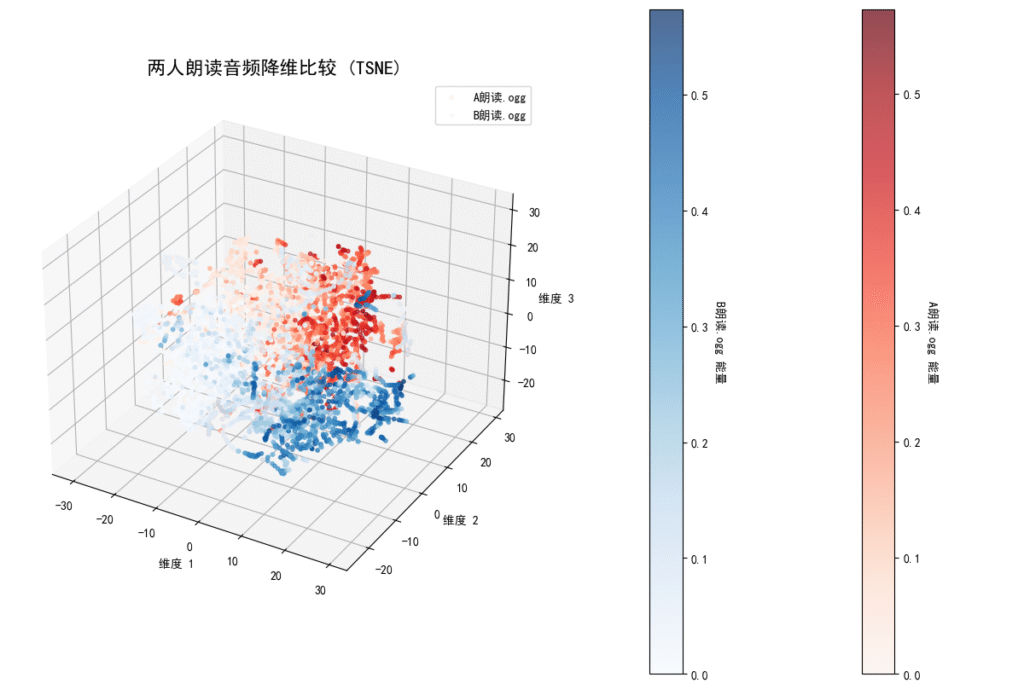
=== 统计分析结果 ===
TSNE
A中心点: [-0.73746437 5.762217 4.046767 ]
B中心点: [ 0.27417228 -5.641561 -3.668627 ]
两人声朗读中心点距离: 13.8057
A分布范围(标准差): [11.39428 9.830946 10.227653]
B分布范围(标准差): [14.40624 9.117463 10.810812]
两人声朗读特征相似度: 差异较大
并且TSNE的结果中,各自的部分采样点连了一起,呈现出一定的线性结构,这与TSNE的原理有关,且也符合发同一音时的变化是连续的特征,产生假设二:能否用这种特性来进行语音识别?也就是比如每个人发“啊”音时,其在空间中的点列形状是相似的,只是位置不同(位置代表了各人发声特点)
扩大实验规模:四人朗读分析
为了验证这一发现的普适性,我又邀请了3位朋友,连上自己一共4人,使用不同的录音设备朗读同一段文字。
PCA结果:
-1024x505.png)
-1024x505.png)
可以发现,在PCA的结果中,整体上看各人的采样点范围重合,部分混杂在了一起,没有清晰的边界,但依然有着各自不同的分布范围。并且我们可以发现高能量(深色)的采样点都集中于维度1的正方向上,有维度1值越大,各人采样点越分散的趋势。
TSNE结果
-1024x505.png)
-1024x399.png)
可以看出TSNE的边界,比PCA结果更加清晰。保留了明显的线性结构,这可能对应着发音时的连续变化过程。
时间维度上的发现
最有趣的是,当我观察声音点在三维空间中随时间变化的动画时,发现那些连成线的结构确实对应着时间上连续的声音片段:
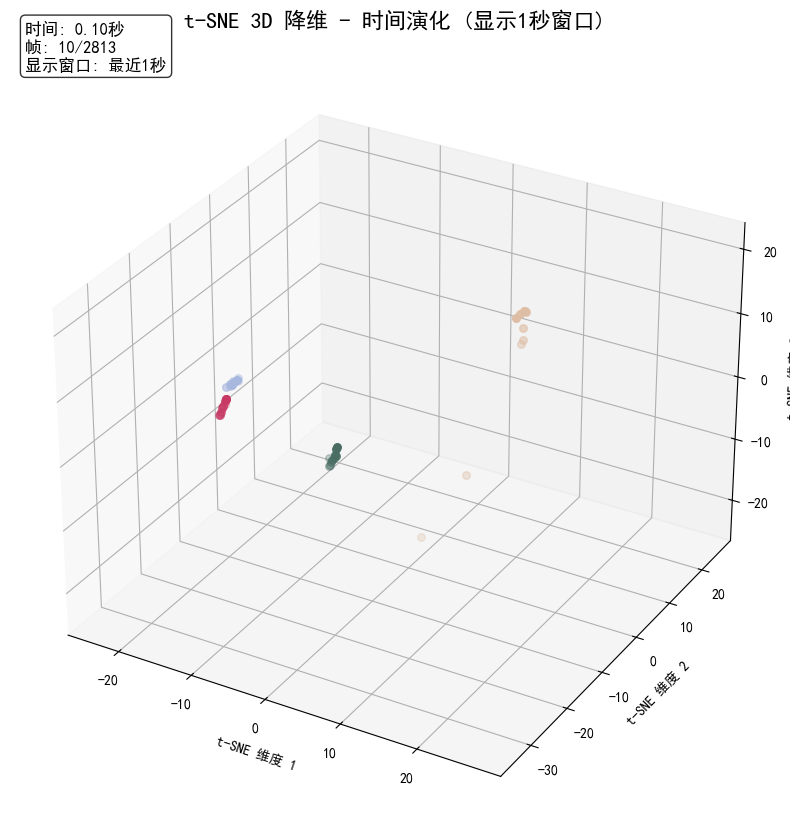
声音点在t-SNE空间中的时间演化,可见连续发音形成线性结构
这提示了一个有趣的可能性:每个人发同一个音时,其在空间中的轨迹形状可能是相似的,只是位置不同——位置反映了个人发声特点,而轨迹形状可能反映了发音内容。
实际应用与展望
这种声音可视化技术有多个潜在应用方向:
- 声纹识别:每个人的声音在特征空间中有独特分布,可用于身份验证
- 语音识别:相似的发音可能在空间中形成相似的轨迹模式
- 医学诊断:某些嗓音疾病可能导致声音在特征空间中的分布异常
- 语音教学:可视化母语者与学习者的发音差异,提供直观反馈
这项探索表明,将声音映射到可视空间不仅能帮助我们理解声音的本质,还可能为声音相关的技术应用提供新的思路。虽然目前的实验还比较简单,但已展现出令人兴奋的可能性。
声音不再只是听觉的体验,通过数据可视化,我们能够”看见”声音的独特指纹,探索每个人声音的独特性。这或许就是那部将鸟叫声可视化的视频背后的深层意义——让我们从新的维度理解和欣赏声音世界的丰富性与多样性。